大数据概论
……
- 数据和信息:信息是较为宏观的概念,它由数据的有序排列组合而成,传达给读者某个概念方法等;而数据则是构成信息的基本单位,离散的数据没有任何使用价值
- 数据类型:文本、图片、音频、视频
- 数据组织形式:文件(word文档、图片文件)数据库
- 大数据的概念:数据量大、数据类型繁多、处理速度快、价值密度低
- 大数据处理流程:数据采集与预处理 -> 数据存储与管理 -> 数据处理与分析 -> 数据可视化
- 云计算特点:初期零成本,后期免维护,在供应IT资源量方面”予取予求“
简答题
云计算服务模式:软件及服务(SaaS)、平台即服务(PaaS)、基础设施及服务(IaaS)
云类型:公有云、私有云、混合云
物联网四个层次
感知层进行信号采集
通过网络层进行传输
传输到指定位置后经过处理层处理
最后达到应用层
RFID原理:RFID 技术的基本工作原理并不复杂,电子标签进入磁场后,接收解读器发出的射频信号,凭借感应电流所获得的能量发送出存储在芯片中的产品信息,或者主动发送某频率的信号。解读器读取信息并解码后,送至中央信息系统进行有关数据处理
硬件:输入设备、输出设备、运算器、控制器、存储器
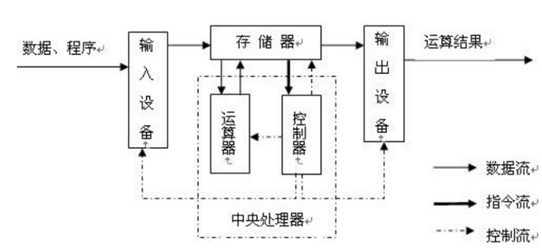
CPU处理指令:CPU 从缓存中取出指令放入指令寄存器,并对指令译码。把指令分解成一系列的微操作,然后发出各种控制命令执行微操作系列,从而完成条指令的执行
计算机网络三个功能
硬件资源共享:硬件资源共享。可以在全网范围内提供对处理资源、存储资源、输入输出资源等昂贵设备的共享,使用户节省投资也便于集中管理和均衡分担负荷
软件资源共享:软件资源共享。允许互联网上的用户远程访问各类大型数据库,可以得到网络文件传送服务、远地进程管理服务和远程文件访问服务,从而避免软件研制上的重复劳动及数据资源的重复存贮,也便于集中管理。
用户间信息交换:用户间信息交换。计算机网络为分布在各地的用户提供了强有力的通信手段。用户可以通过计算机网络传送电子邮件、发布新闻消息和进行电子商务活动。
常见的网络互联设备:中继器、网桥、路由器、网关、集线器、交换机
OSI参考模型对应TCP/IP五层模型
| OSI参考模型 | TCP/IP五层模型 |
|---|---|
| 应用层 | 应用层 |
| 表示层 | 应用层 |
| 会话层 | 应用层 |
| 传输层 | 传输层 |
| 网络层 | 网络层 |
| 数据链路层数据链路层 | 数据链路层数据链路层 |
| 物理层 | 物理层 |
- 数据采集的三大要点:全面性、多维性、高效性
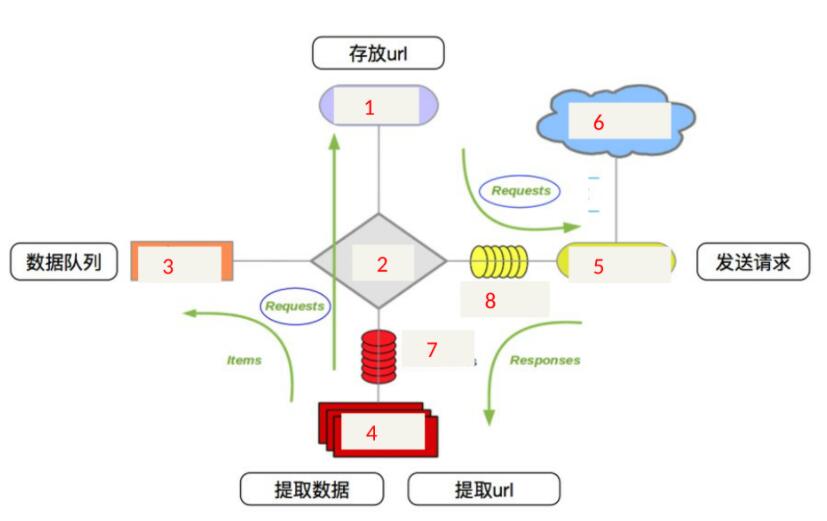
| 1、调度器 | 5、下载器 |
|---|---|
| 2、引擎 | 6、互联网 |
| 3、项目管道 | 7、爬虫中间件 |
| 4、爬虫 | 8、下载器中间件 |
Scrapy工作流也叫作“运行流程’呈”或叫作“数据处理流程’整个数据处理流程由Scrapy引擎进行控制,其主要的运行步骤如下:
①Scrapy引擎从调度器中取出一个链接(URL)用于接下来的抓取;
②Scrapy引擎把URL封装成一个请求并传给下载器;
③下载器把资源下载下来,并封装成应答包;
④爬虫解析应答包;
⑤如果解析出的是项目,则交给项目管道进行进一步的处理;
⑥如果解析出的是链接( URL )则把URL交给调度器等待抓取。
数据转换策略
平滑处理:帮助除去数据中的噪声
聚集处理:对数据进行汇总操作
数据泛化处理:用更抽象(更高层次)的概念来取代低层次的数据对象
规范化处理:将属性值按比例缩放,使之落入一个特定的区间
属性构造处理:根据已有属性集构造新的属性
基于内存的分布式计算框架Spark
在实际应用中,大数据处理主要包括以下三个类型:
复杂的批量数据处理:通常时间跨度在数十分钟到数小时之间
基于历史数据的交互式查询:通常时间跨度在数十秒到数分钟之间
基于实时数据流的数据处理:通常时间跨度在数百毫秒到数秒之间
计算题


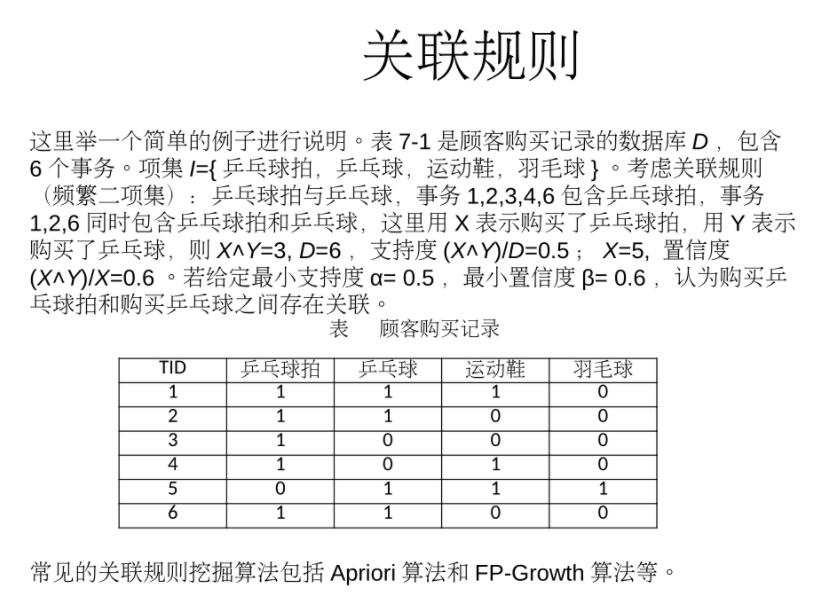
支持度:(X^Y)/D
置信度:(X^Y)/X
论述题
电影推荐系统如何实现?
- 搭建环境,安装 Linux系统、JDK、关系型数据库 MySQL、大数据软件 Hadoop、大数据软件Spark、开发工具 IntelliJ IDEA、ETL 工具Kettle 和 Node.js;
- 数据采集,编写 Scrapy爬虫从网络上获取电影评分数据;
- 加载数据,使用ETL 工具Kettle 对数据进行清洗后加载到分布式文件系统 HDFS中。
- 数据存储和管理,使用分布式文件系统 HDFS和关系数据库 MySQL 对数据进行存储和管理 。
- 数据分析和处理,使用 Scala语言和开发工具IntelliJ IDEA,编写Spark MLlib 程序,根据 HDFS中的大量数据进行模型训练,然后使用训练得到的模型进行电影评分预测,并为用户推荐评分高的电影。
- 可视化,使用Node.js 搭建网站,接受用户访问,并以可视化方式呈现电影推荐结果。

